Home · Publications · More
Publications [Google Scholar]
* indicates equal contribution, ✉ indicates corresponding / co-corresponding author
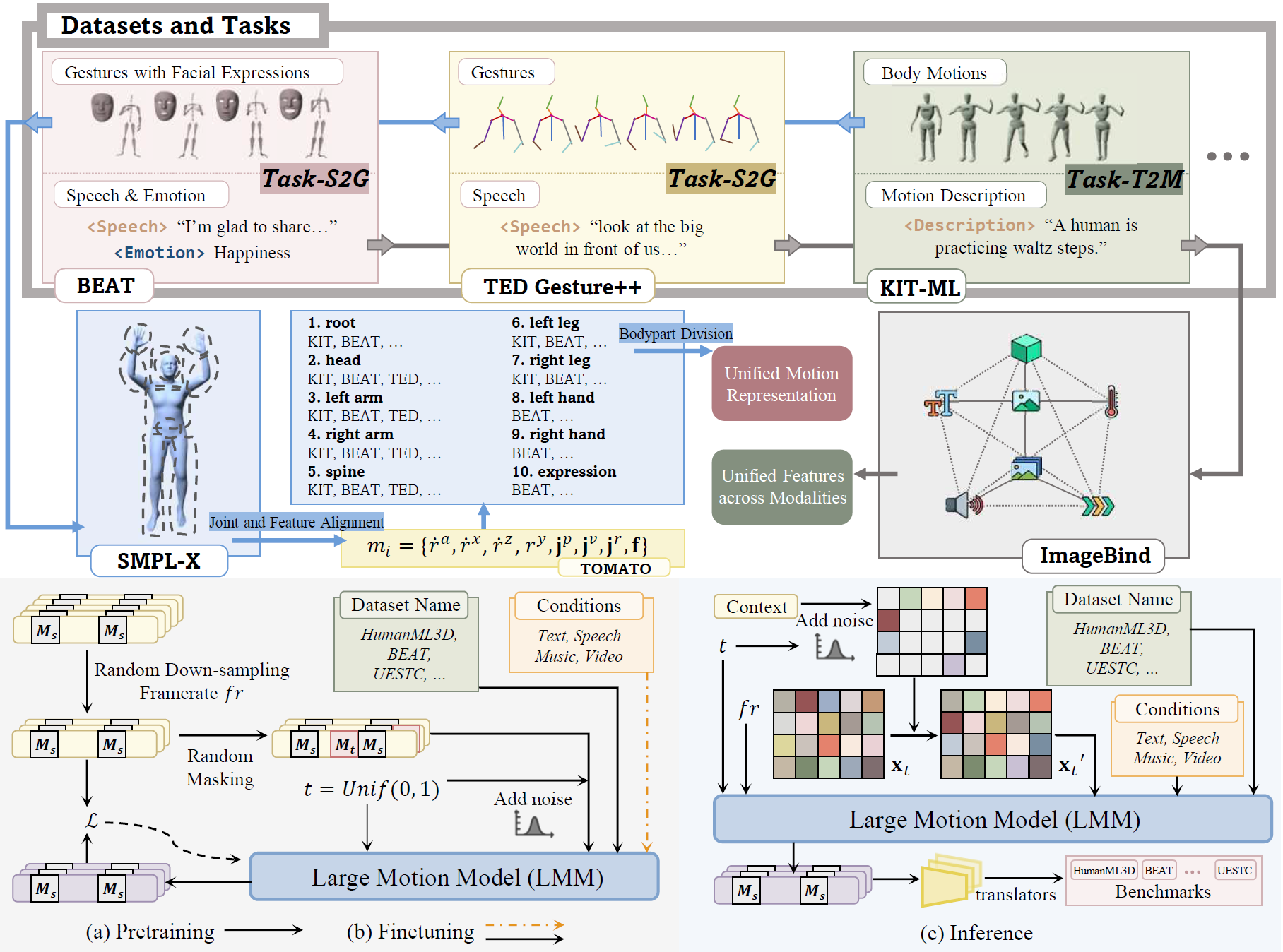 |
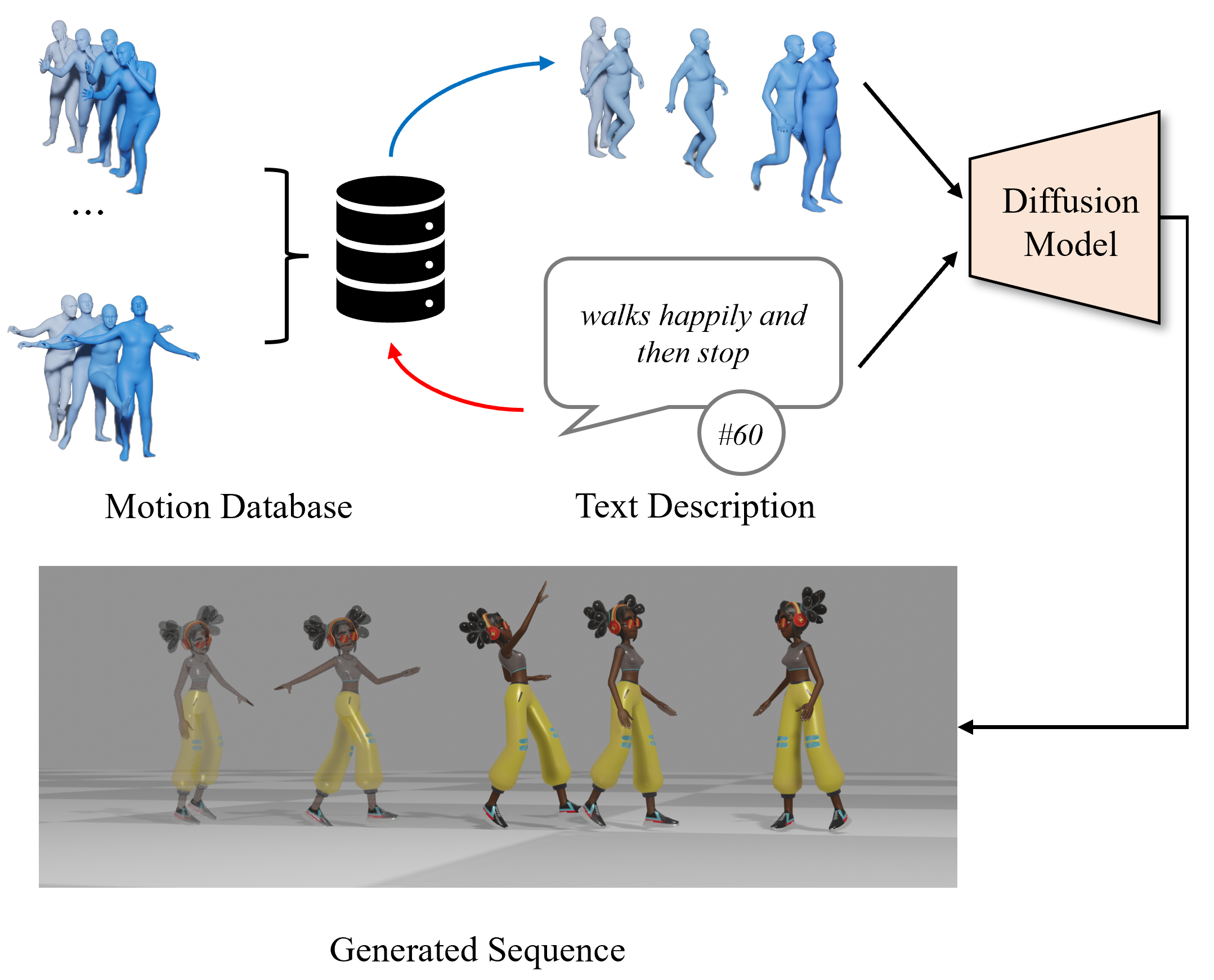
arXiV, 2024 [Paper] [Project Page] [Video] [Code] Star The Large Motion Model (LMM) unifies various motion generation tasks into a scalable, generalist model, demonstrating broad applicability and strong generalization across diverse tasks.
|
 |
Conference on Computer Vision and Pattern Recognition (CVPR), 2024 [Paper] [Project Page] [Code] Digital Life Project is a framework utilizing language as the universal medium to build autonomous 3D characters, who are capable of engaging in social interactions and expressing with articulated body motions, thereby simulating life in a digital environment.
|
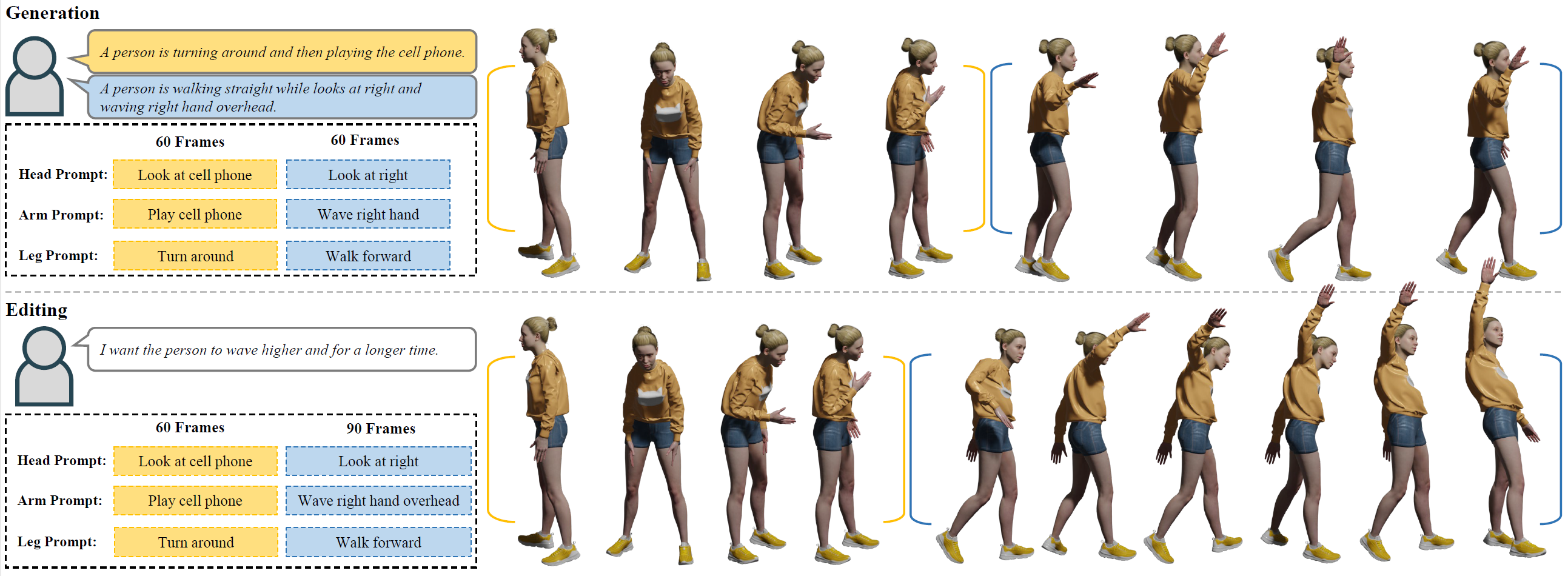 |
Neural Information Processing Systems (NeurIPS), 2023 [Paper] [Project Page] [Code] Star FineMoGen is a diffusion-based motion generation and editing framework that can synthesize fine-grained motions, with spatial-temporal composition to the user instructions.
|
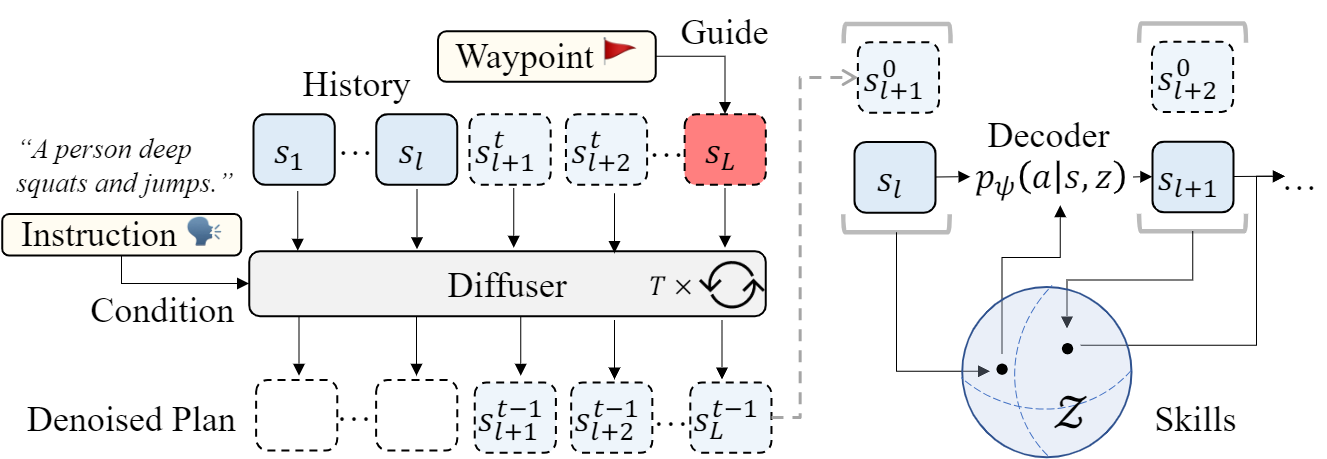 |
Neural Information Processing Systems (NeurIPS), 2023 [Paper] [Project Page] [Code] Star InsActor is a principled generative framework that leverages recent advancements in diffusion-based human motion models to produce instruction-driven animations of physics-based characters.
|
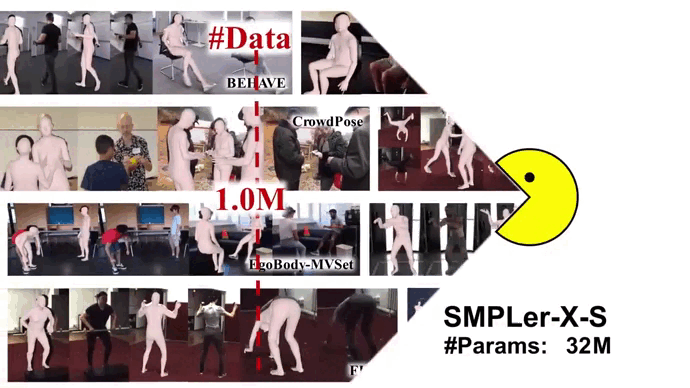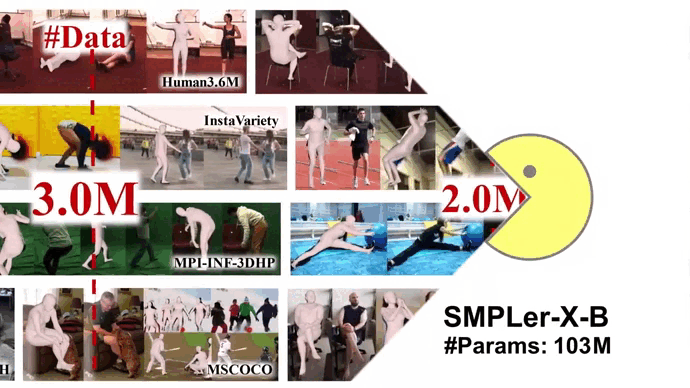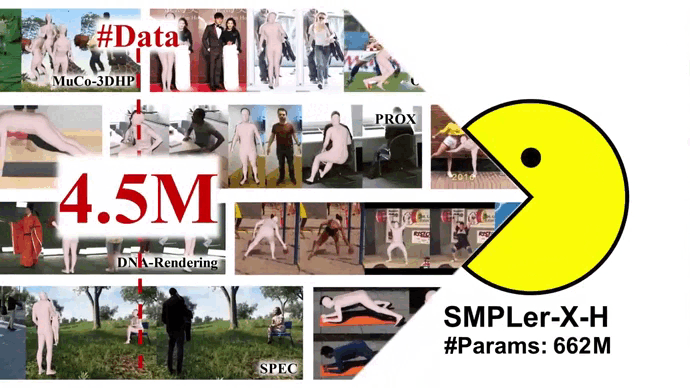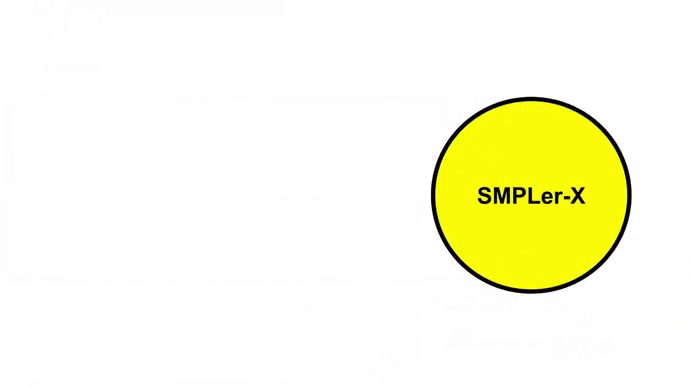 |
Neural Information Processing Systems (NeurIPS Datasets and Benchmarks Track), 2023 [Paper] [Project Page] [Code] Star SMPLer-X is the first generalist foundation model for Expressive human pose and shape estimation (EHPS). With big data and the large model, SMPLer-X exhibits strong performance across diverse test benchmarks and excellent transferability to even unseen environments.
|
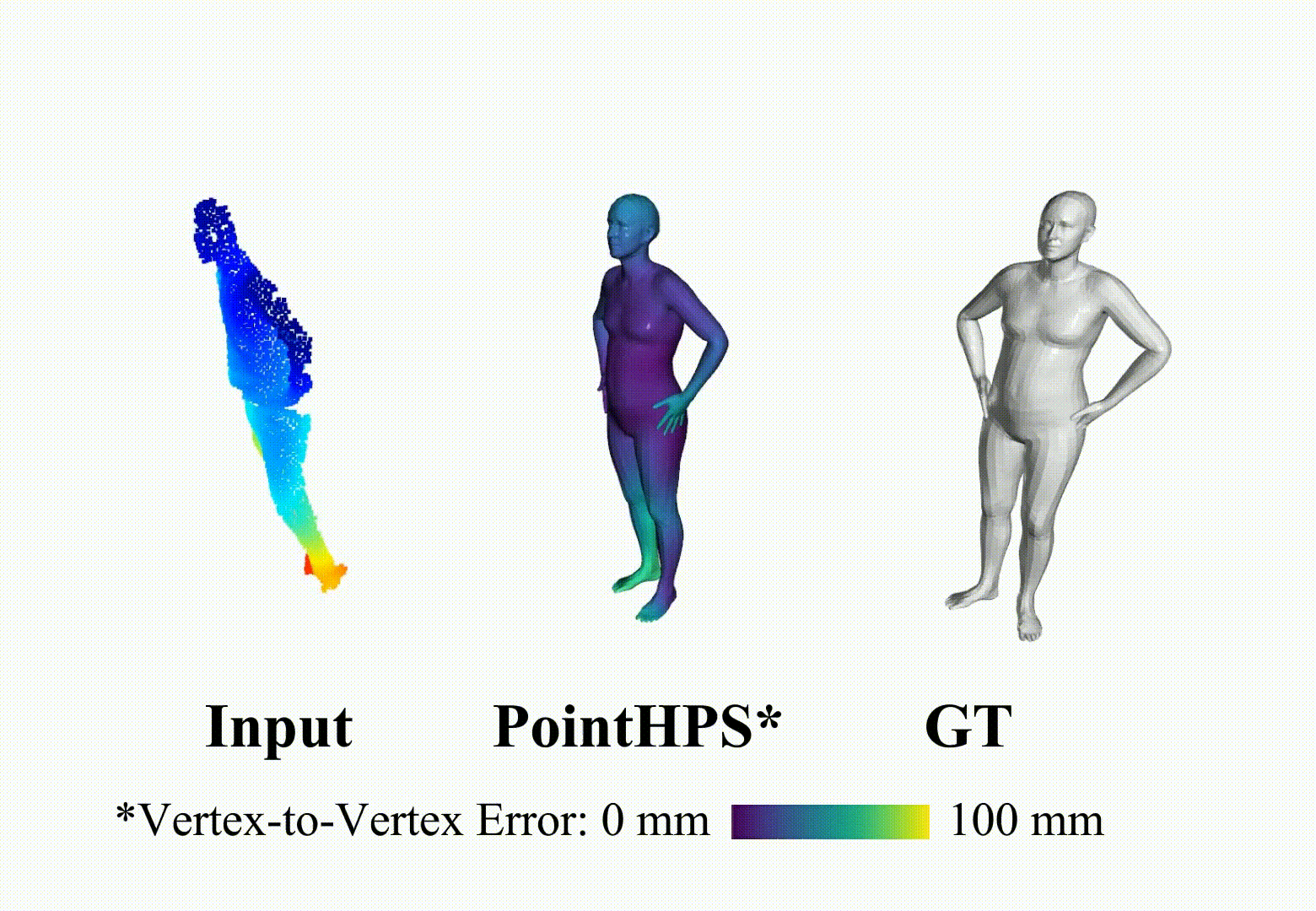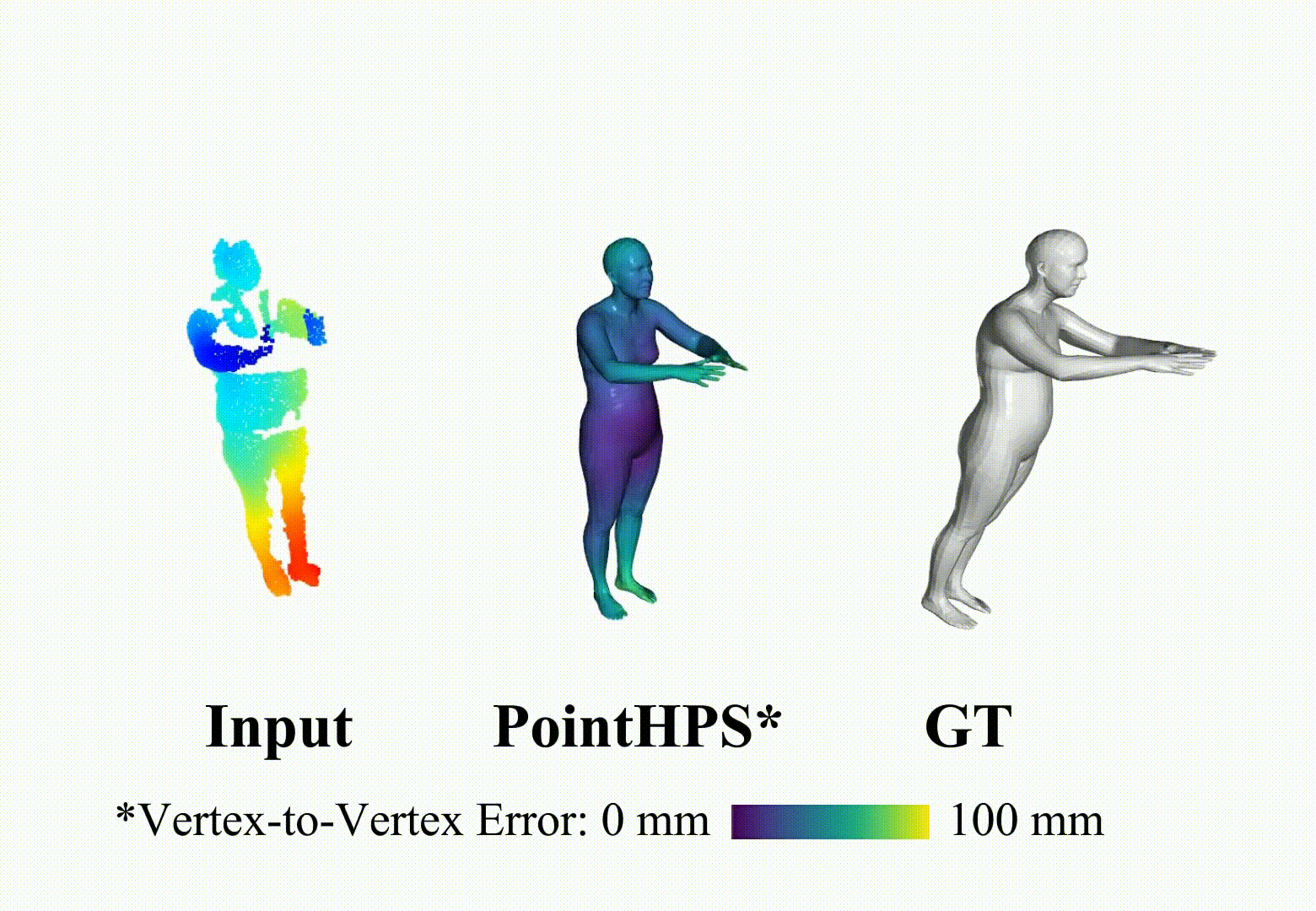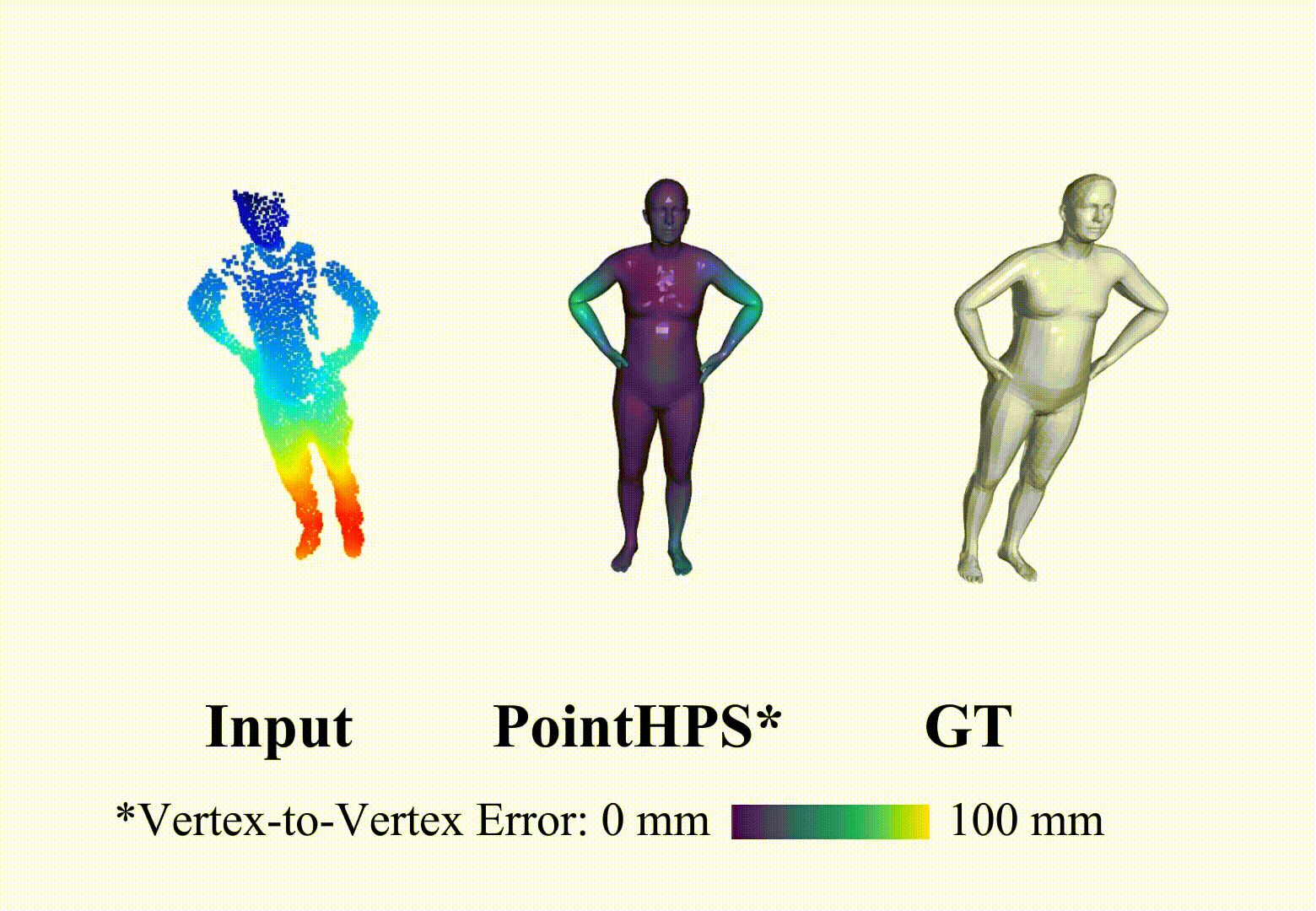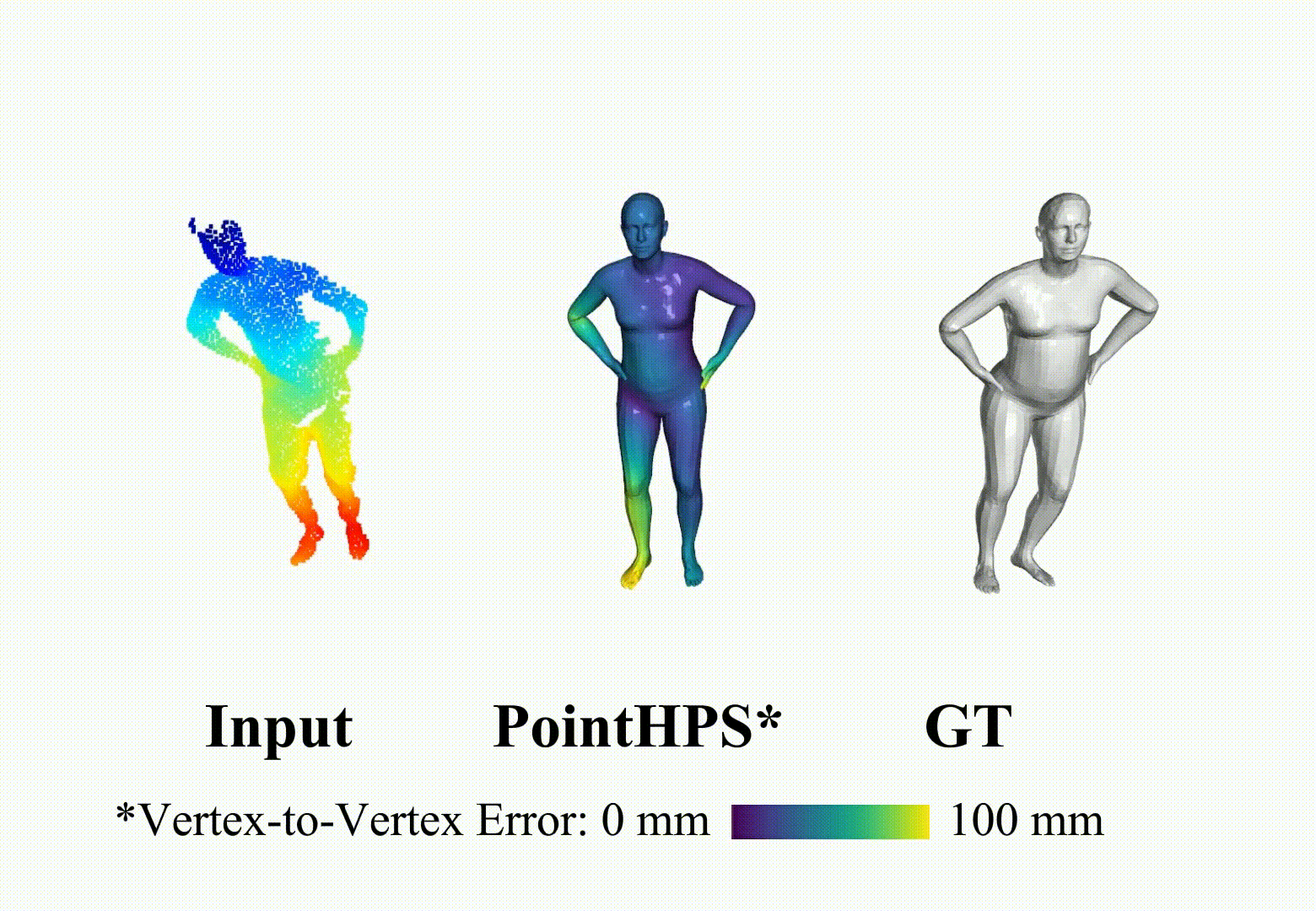 |
ArXiV, 2023 [Paper] [Project Page] [Video] [Code] Star PointHPS iteratively refines point features through a cascaded architecture to achieve more accurate 3D Human pose and shape estimation(HPS) from point clouds.
|
 |
International Conference on Computer Vision (ICCV), 2023 [Paper] [Project Page] [Video] [Code] [Colab Demo] [Hugging Face Demo] Star ReMoDiffuse is a retrieval-augmented 3D human motion diffusion model. Benefiting from the extra knowledge from the retrieved samples, ReMoDiffuse is able to achieve high-fidelity on the given prompts.
|
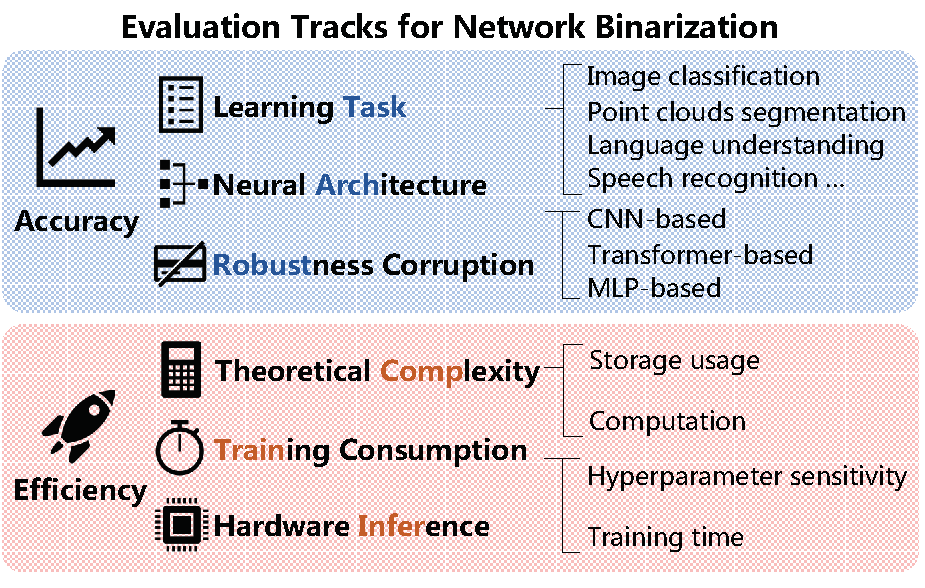 |
International Conference on Machine Learning (ICML), 2023 [Paper] A rigorously designed benchmark with in-depth analysis for network binarization. It first carefully scrutinizes the requirements of binarization in the actual production and define evaluation tracks and metrics for a comprehensive and fair investigation.
|
 |
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 [Paper] [Project Page] [Video] [Code] [Colab Demo] [Hugging Face Demo] Star The first text-driven motion generation pipeline based on diffusion models with probabilistic mapping, realistic synthesis and multi-level manipulation ability.
|
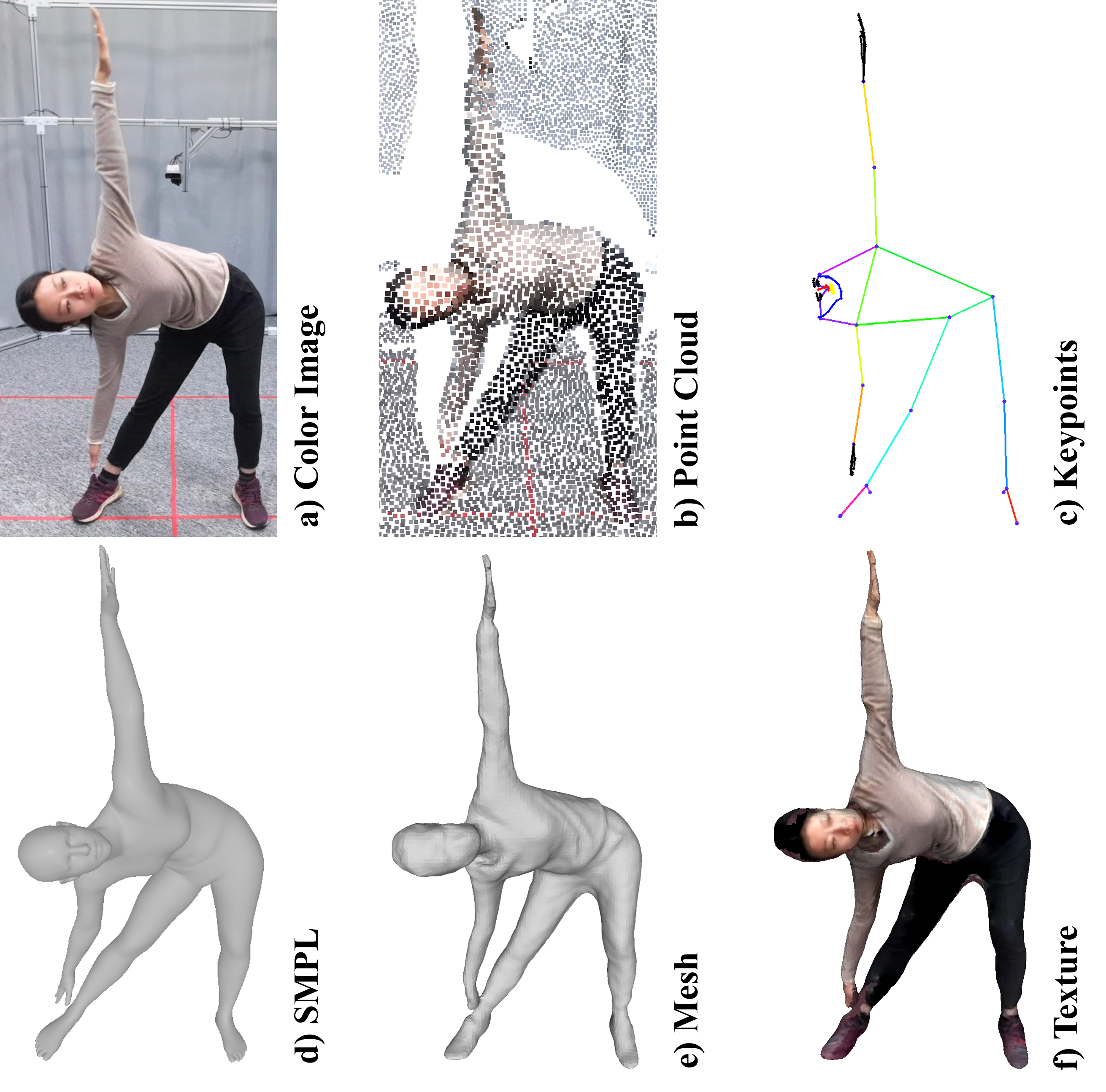 |
European Conference on Computer Vision (ECCV), 2022 (Oral Presentation) [Paper] [Project Page] [Video] A large-scale multi-modal(color images, point clouds, keypoints, SMPL parameters, and textured meshes) 4D human dataset with 1000 human subjects, 400k sequences and 60M frames.
|
|
ACM Transactions on Graphics (SIGGRAPH), 2022 [Paper] [Project Page] [Video] [Code] [Colab Demo] Star AvatarCLIP is the first zero-shot text-driven pipeline, which empowers layman users to generate and animate 3D Avatars by natural language description.
|
|
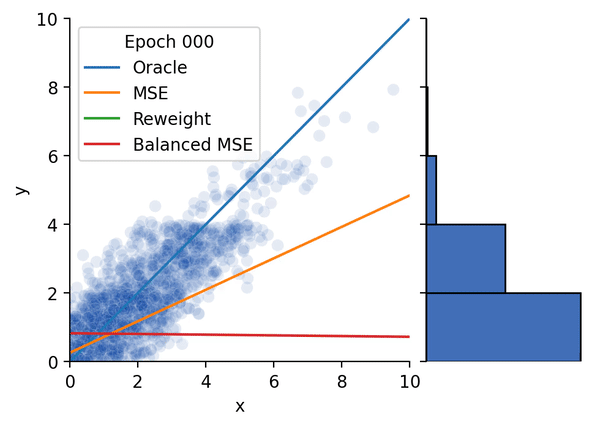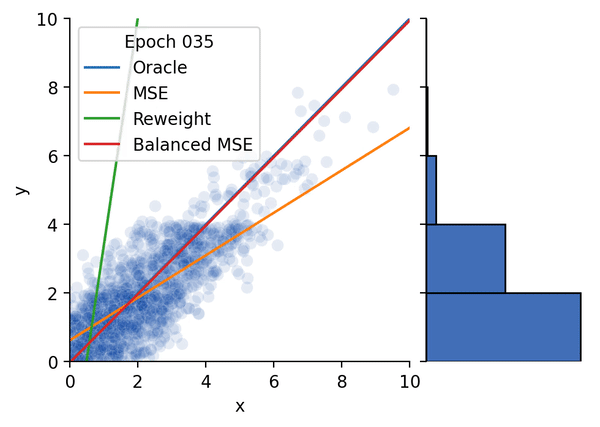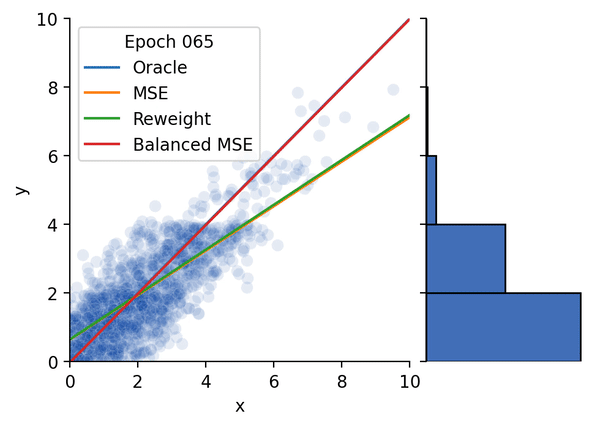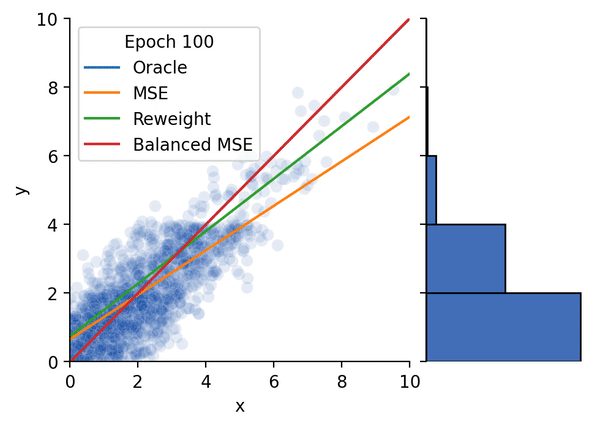 |
Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (Oral Presentation) [Paper] [Project Page] [Talk] [Code] [Hugging Face Demo] Star A statistically principled loss function to address the train/test mismatch in imbalanced regression, coincides with the supervised contrastive loss.
|
 |
Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [Paper] [Code] Star A systematical comparison of the generalization ability between CNNs and ViTs. Three representative generalization-enhancement techniques are applied to ViTs to further explore their inner properties.
|
 |
Zhongang Cai*,
Mingyuan Zhang*,
Jiawei Ren*,
Chen Wei,
Daxuan Ren,
Zhengyu Lin,
Haiyu Zhao,
Lei Yang,
Chen Change Loy,
Ziwei Liu✉
arXiV, 2021 [Paper] [Code] Star A large-scale synthetic human dataset collected using GTA-5 game engine, providing stable performance boost to both frame-based and video-based HMR.
|
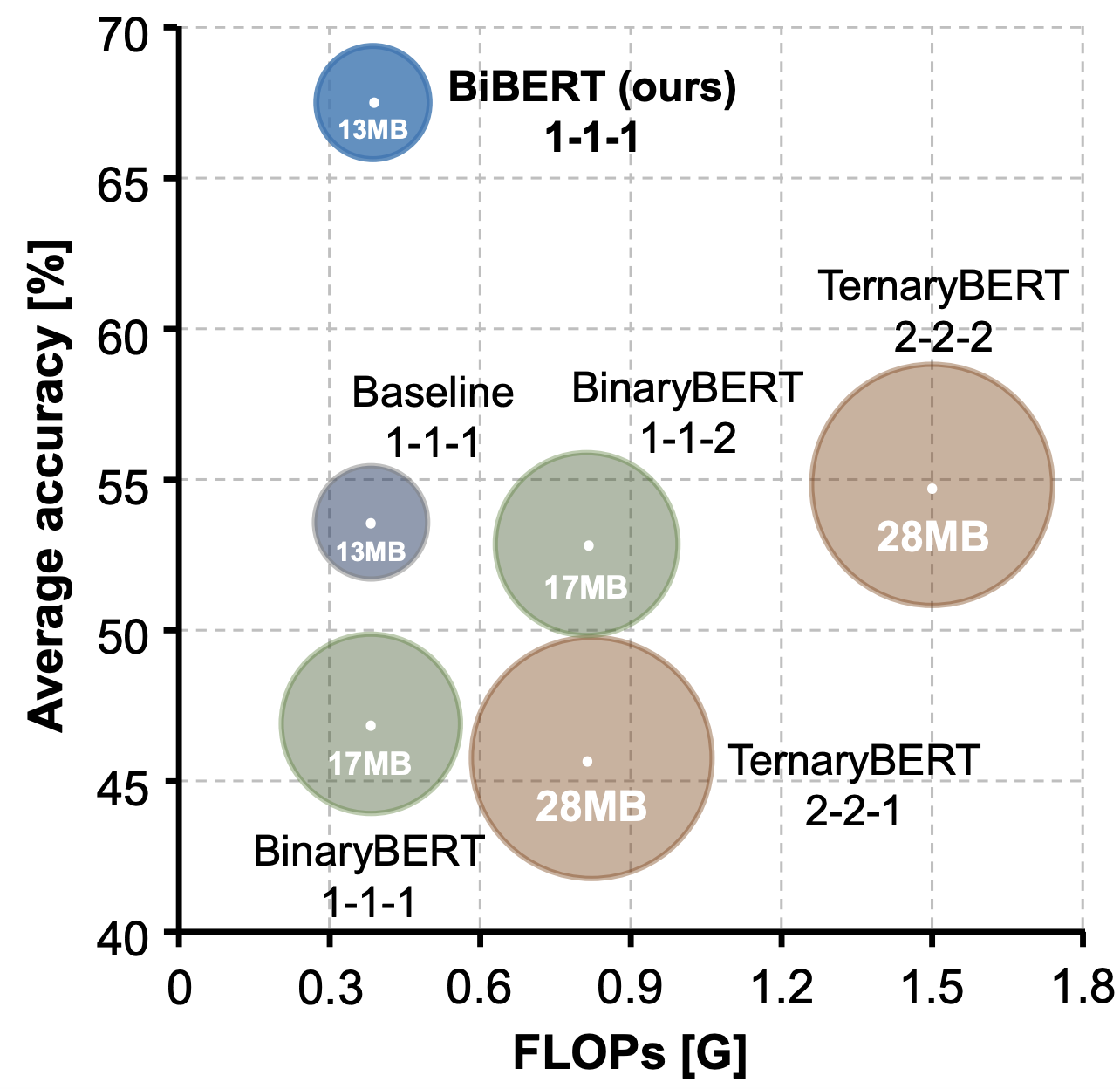 |
International Conference on Learning Representations (ICLR), 2022 [Paper] [Code] Star BiBERT is the first fully binarized BERT. It introduces an efficient Bi-Attention structure and a DMD scheme, which yields impressive 59.2x and 31.2x saving on FLOPs and model size.
|
 |
Association for the Advancement of Artificial Intelligence (AAAI), 2021 [Paper] [Project Page] REFINE achieves high-quality panoptic segmentation by improving cross-task prediction fusion, and within-task prediction fusion.
|
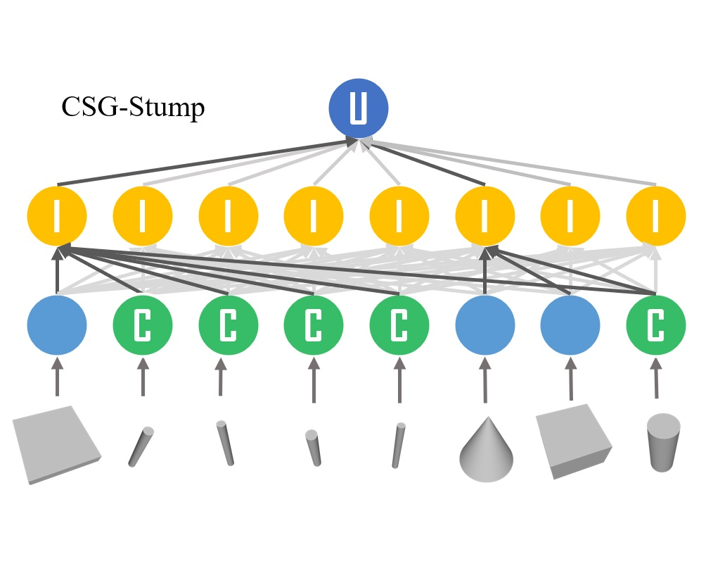 |
International Conference on Computer Vision (ICCV), 2021 [Paper] [Project Page] [Code] Star CSG-Stump learns shapes from point clouds and discovers the underlying constituent modeling primitives and operations.
|
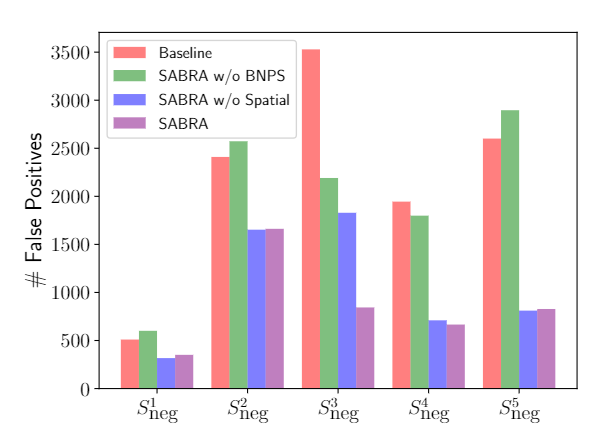 |
British Machine Vision Conference (BMVC), 2021 [Paper] SABRA explores the imbalanced distribution in Human-Object Interaction detection. It further proposes a new pipeline to equip the model with sufficient spatial information.
|
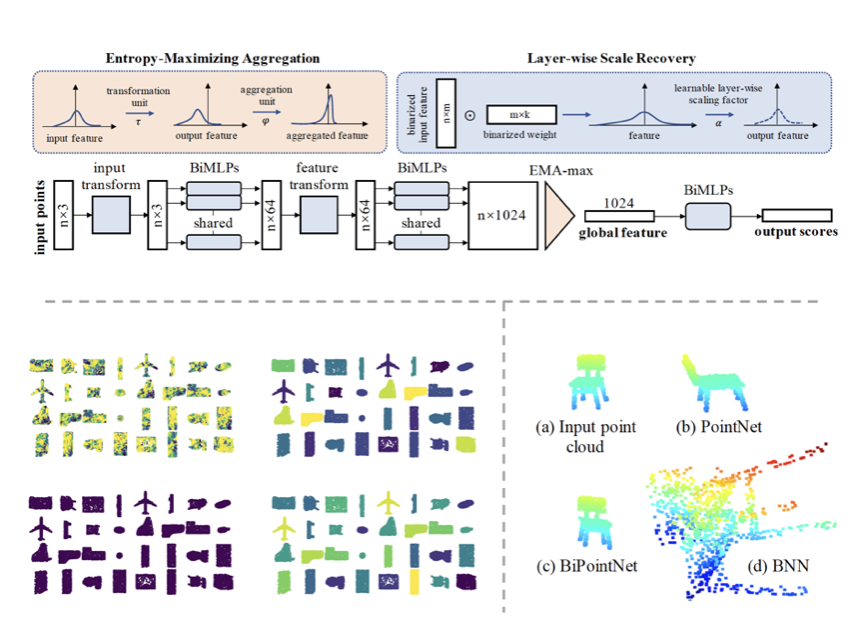 |
International Conference on Learning Representations (ICLR), 2021 [Paper] [Code] Star BiPointNet is the first fully binarized network for point cloud learning. BiPointNet gives an impressive 14.7x speedup and 18.9x storage saving on real-world resource-constrained devices.
|
 |
Winter Conference on Applications of Computer Vision (WACV), 2021 [Paper] [Code] Star Efficient Attention reduces the memory and computational complexities of the attention mechanism from quadratic to linear. It demonstrates significant improvement in performance-cost trade-offs on a variety of tasks including object detection, instance segmentation, stereo depth estimation, and temporal action lcoalization.
|
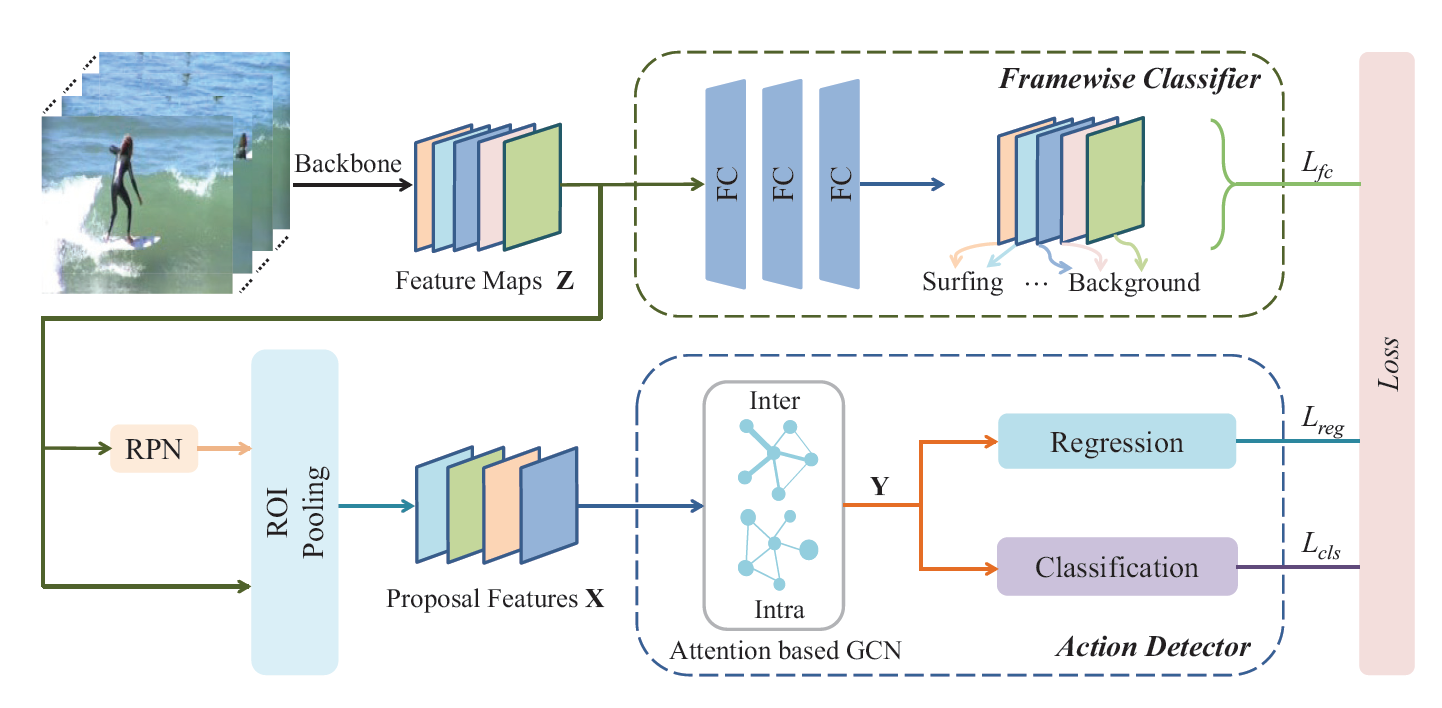 |
Association for the Advancement of Artificial Intelligence (AAAI), 2020 [Paper] AGCN-P-3DCNNs fuses intra and inter attention to model intra long-range dependencies and inter dependencies simultaneously. It also contains a simple and effective framewise classifier, which enhances the feature presentation capabilities of backbone model.
|
Updated: 2024-5-8