Abstract
3D human motion generation is crucial for creative industry. Recent advances rely on generative models with domain knowledge for text-driven motion generation, leading to substantial progress in capturing common motions. However, the performance on more diverse motions remains unsatisfactory. In this work, we propose ReMoDiffuse, a diffusion-model-based motion generation framework that integrates a retrieval mechanism to refine the denoising process. ReMoDiffuse enhances the generalizability and diversity of text-driven motion generation with three key designs: 1) Hybrid Retrieval finds appropriate references from the database in terms of both semantic and kinematic similarities. 2) Semantic-Modulated Transformer selectively absorbs retrieval knowledge, adapting to the difference between retrieved samples and the target motion sequence. 3) Condition Mixture better utilizes the retrieval database during inference, overcoming the scale sensitivity in classifier-free guidance. Extensive experiments demonstrate that ReMoDiffuse outperforms state-of-the-art methods by balancing both text-motion consistency and motion quality, especially for more diverse motion generation.
Method
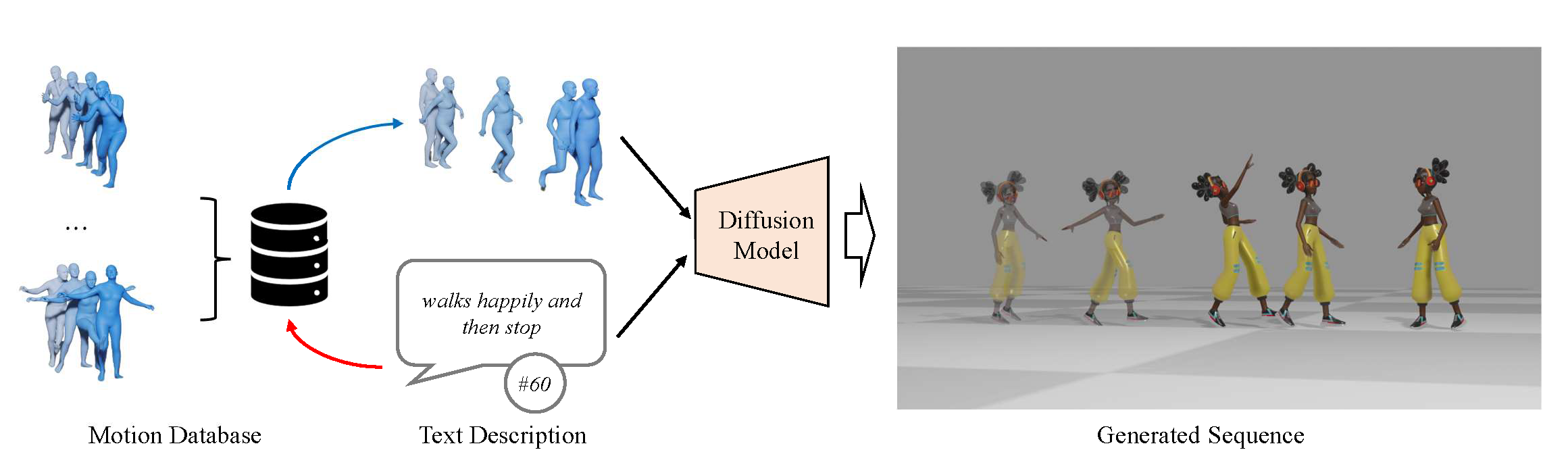
Figure 1. Pipeline Overview.
ReMoDiffuse is a retrieval-augmented 3D human motion diffusion model. Benefiting from the extra knowledge from the retrieved samples, ReMoDiffuse is able to achieve high-fidelity on the given prompts.
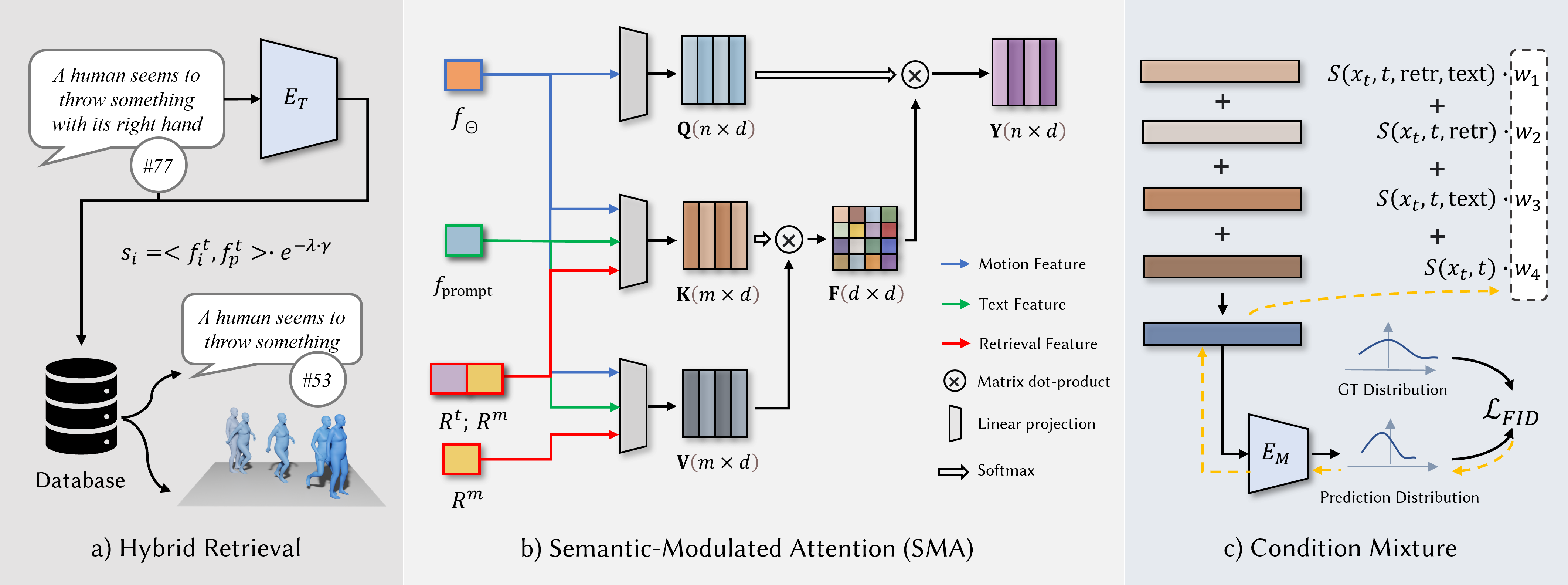
Figure 2. Main components of the proposed ReMoDiffuse.
a) Hybrid retrieval database stores various features of each training data. The pre-processed text feature and relative difference of motion length are sent to calculate the similarity with the given language description. The most similar ones are fed into the semantics-modulated transformer (SMT), serving as additional clues for motion generation. b) Semantics-modulated transformer (SMT) incorporates \(N\) identical decoder layers, including a semantics-modulated attention (SMA) layer and an FFN layer. The figure shows the detailed architecture of SMA module. CLIP's extracted text features \(f_{prompt}\) from the given prompt, features \(R^t\) and \(R^m\) from the retrieved samples, and current motion features \(f_{\Theta}\) will further refine the noised motion sequence. c) Condition mixture. To synthesize diverse and realistic motion sequences, starting from the pure noised sample, the motion transformer repeatedly eliminates the noise. To better mix outputs under different combinations of conditions, we suggest a training strategy to find the optimal hyper-parameters \(w_1\), \(w_2\), \(w_3\) and \(w_4\).
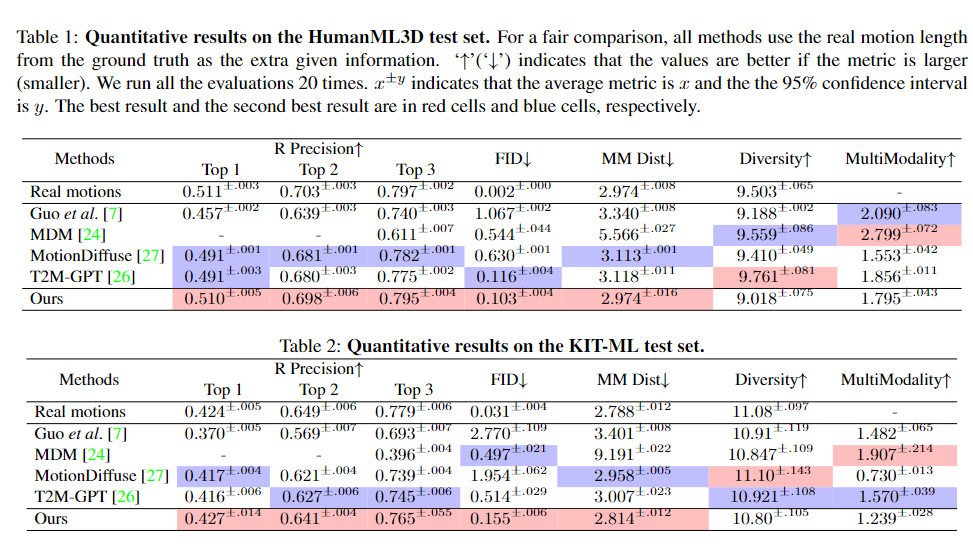
Quantitative Results
Qualitative Results
Fantastic Human Generation Works 🔥
Motion Generation
⇨ MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
⇨ Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
2D Human Generation
⇨ Text2Human: Text-Driven Controllable Human Image Generation
⇨ StyleGAN-Human: A Data-Centric Odyssey of Human Generation
3D Human Generation
⇨ EVA3D: Compositional 3D Human Generation from 2D Image Collections
⇨ AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
BibTeX
@article{zhang2023remodiffuse,
title = {ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model},
author = {Zhang, Mingyuan and
Guo, Xinying and
Pan, Liang and
Cai, Zhongang and
Hong, Fangzhou and
Li, Huirong and
Yang, Lei and
Liu, Ziwei},
year = {2023},
journal = {arXiv preprint arXiv:2304.01116},
}Acknowledgement
This work is supported by NTU NAP, MOE AcRF Tier 2 (T2EP20221-0033), and under the RIE2020 Industry Alignment Fund - Industry Collaboration Projects (IAF-ICP) Funding Initiative, as well as cash and in-kind contribution from the industry partner(s).
We referred to the project page of Nerfies when creating this project page.