FineMoGen: Fine-Grained Spatio-Temporal Motion Generation and Editing
Accepted to NeurIPS 2023
Abstract
Text-driven motion generation has achieved substantial progress with the emergence of diffusion models. However, existing methods still struggle to generate complex motion sequences that correspond to fine-grained descriptions, depicting detailed and accurate spatio-temporal actions. This lack of fine controllability limits the usage of motion generation to a larger audience. To tackle these challenges, we present FineMoGen, a diffusion-based motion generation and editing framework that can synthesize fine-grained motions, with spatial-temporal composition to the user instructions. Specifically, FineMoGen builds upon diffusion model with a novel transformer architecture dubbed Spatio-Temporal Mixture Attention (SAMI). SAMI optimizes the generation of the global attention template from two perspectives: 1) explicitly modeling the constraints of spatio-temporal composition; and 2) utilizing sparsely-activated mixture-of-experts to adaptively extract fine-grained features. To facilitate a large-scale study on this new fine-grained motion generation task, we contribute the HuMMan-MoGen dataset, which consists of 2,968 videos and 102,336 fine-grained spatio-temporal descriptions. Extensive experiments validate that FineMoGen exhibits superior motion generation quality over state-of-the-art methods. Notably, FineMoGen further enables zero-shot motion editing capabilities with the aid of modern large language models (LLM), which faithfully manipulates motion sequences with fine-grained instructions.
Method
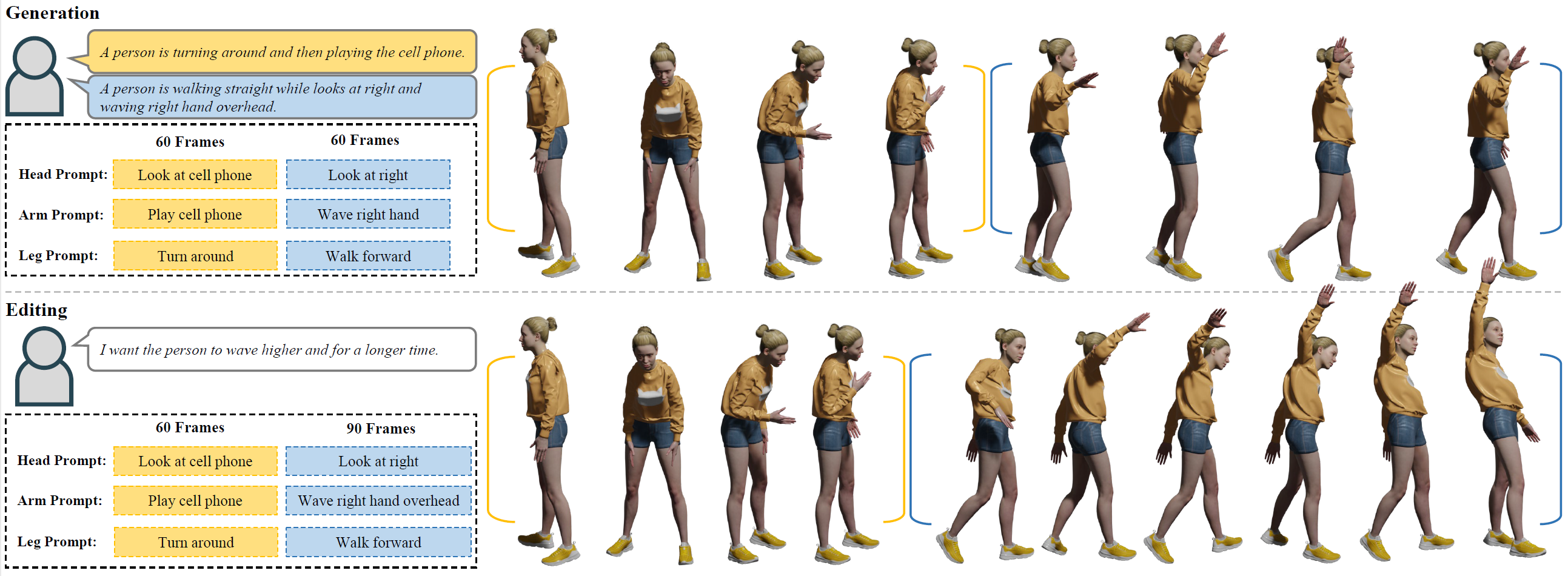
Figure 1. Pipeline Overview.
FineMoGen is a motion diffusion model that can accept fine-grained spatio-temporal descriptions. The synthesized motion sequences are natural and consistent with the given conditions. With the assistance of Large Language Model (LLM), users can interactively edit the generated sequence.
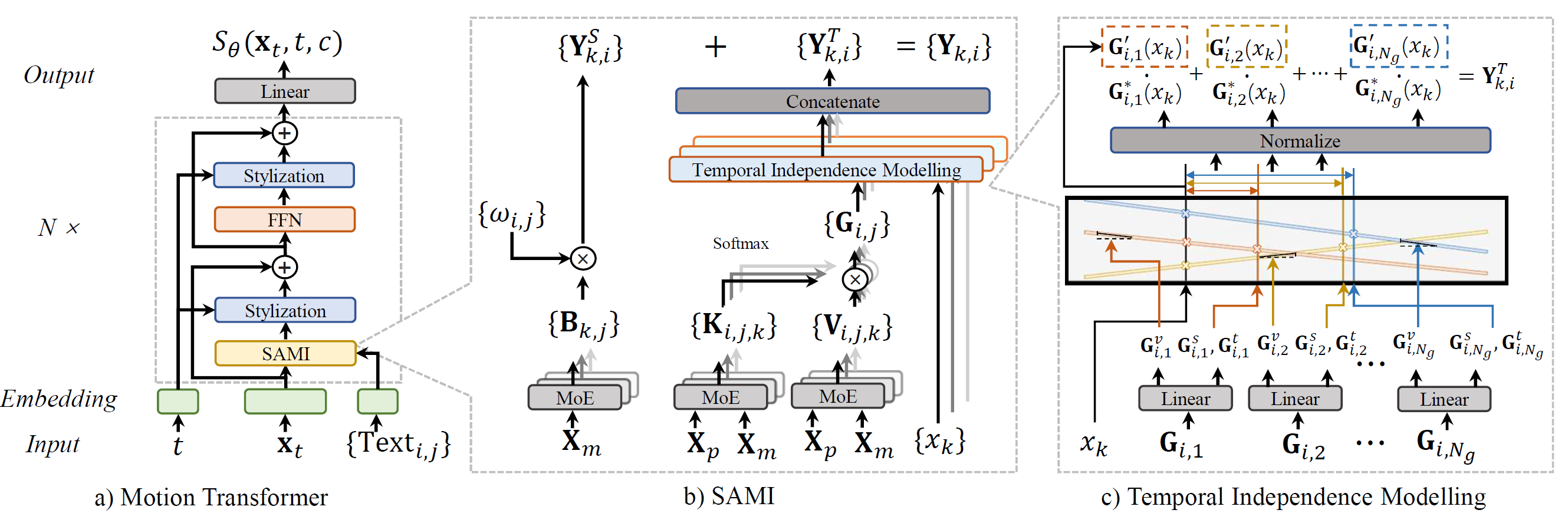
Figure 2. Main components of the proposed FineMoGen.
In Figure (a), our employed Motion Transformer first encodes the timestamp \(t\), the noise-infused motion sequence \(\mathbf{x}_t\), and descriptions \(\mathrm{Text}_{i,j}\) into feature vectors, which undergo further processing by \(N\) layers. Central to these layers lies our proposed SAMI, which takes into account both spatial independence and temporal independence. In Figure (b)'s left segment, the feature fusion among different body parts is demonstrated. This fusion is driven by a sequence of learnable parameters \(\omega_{i,j}\) and the enhanced feature \(\mathbf{B}_{k,j}\) derived from MoE projection. The outcome of this spatial modeling is denoted as the feature vector \(\mathbf{Y}^S_{k,i}\) Figure (b)'s right segment illustrates the process of temporal modeling. Initially, text features and motion features are concatenated and fed into MoE layers, yielding informative features \(\mathbf{K}_{i,j,k}\) and \(\mathbf{V}_{i,j,k}\). These two feature vectors are then merged into global templates \(\mathbf{G}_{i,j}\). For each time moment, the refined feature is obtained from these global templates through temporal independence modeling, as depicted in Figure (c). Here, we generate \(N_g\) time-varying signals. After normalization by the time differences between \(x_k\) and time anchors \(\mathbf{G}_{i,j}^t\), we ultimately acquire the refined feature \(\mathbf{Y}^T_{k,i}\). Upon summation with \(\mathbf{Y}^S_{k,i}\), the final output of SAMI, denoted as \(\mathbf{Y}_{k,i}\), is achieved.
HuMMan-MoGen Dataset
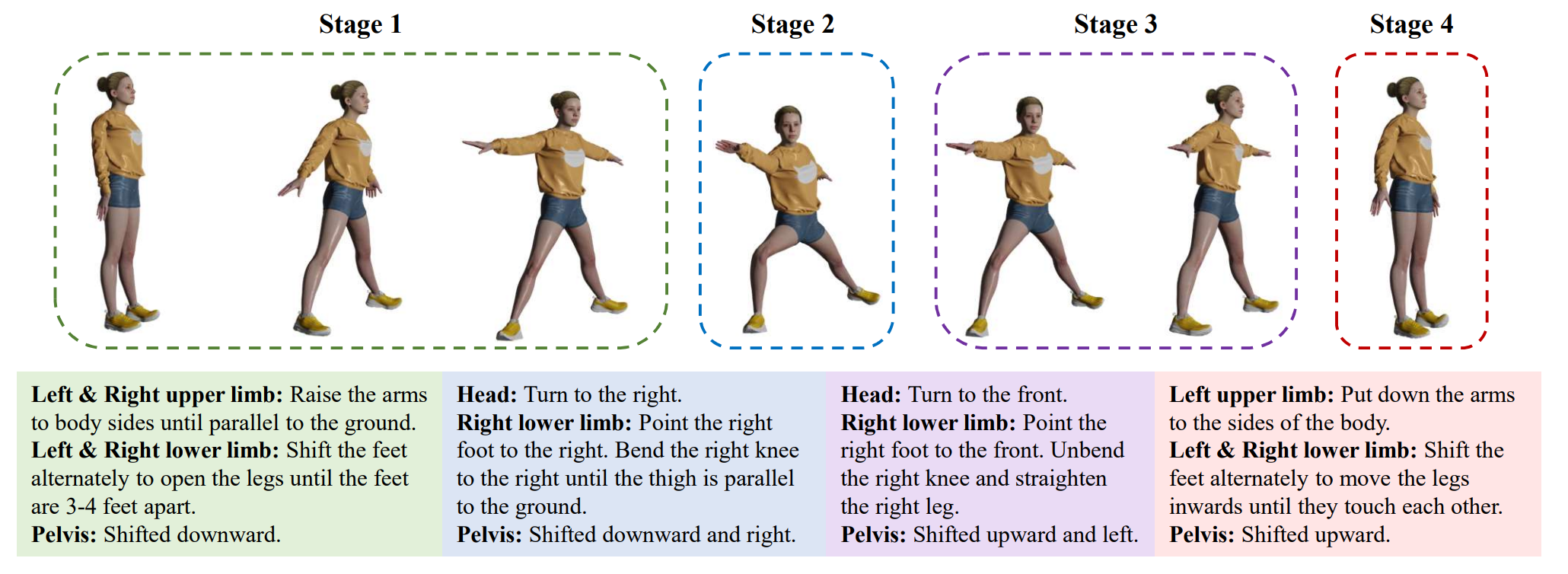
Examples of spatial-temporal fine-grained annotation. Due to the space limitation, we only show the most significant body parts.
Fantastic Human Generation Works 🔥
Motion Generation
⇨ InsActor: Instruction-driven Physics-based Characters
⇨ ReMoDiffuse: ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
⇨ DiffMimic: Efficient Motion Mimicking with Differentiable Physics
⇨ MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
⇨ Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
2D Human Generation
⇨ Text2Performer: Text-Driven Human Video Generation
⇨ Text2Human: Text-Driven Controllable Human Image Generation
⇨ StyleGAN-Human: A Data-Centric Odyssey of Human Generation
3D Human Generation
⇨ EVA3D: Compositional 3D Human Generation from 2D Image Collections
⇨ AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
BibTeX
@article{zhang2023finemogen,
title = {FineMoGen: Fine-Grained Spatio-Temporal Motion Generation and Editing},
author = {Zhang, Mingyuan and
Li, Huirong and
Cai, Zhongang and
Ren, Jiawei and
Yang, Lei and
Liu, Ziwei},
year = {2023},
journal = {NeurIPS},
}Acknowledgement
This work is supported by NTU NAP, MOE AcRF Tier 2 (T2EP20221-0033), and under the RIE2020 Industry Alignment Fund - Industry Collaboration Projects (IAF-ICP) Funding Initiative, as well as cash and in-kind contribution from the industry partner(s).
We referred to the project page of Nerfies when creating this project page.