Abstract
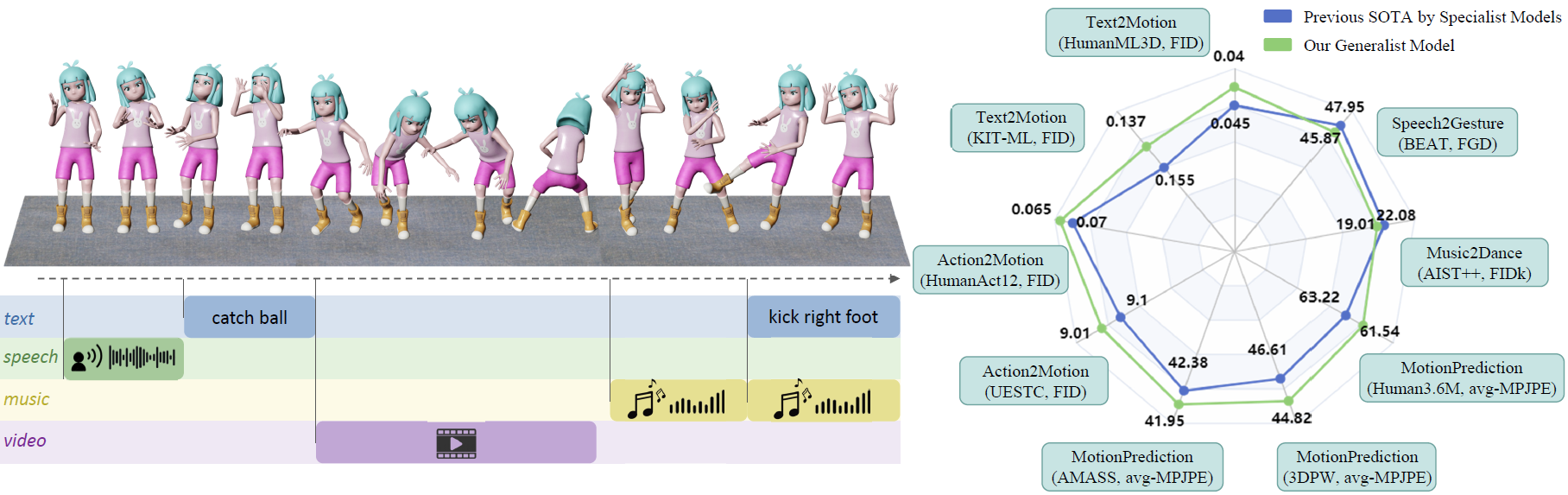
Human motion generation, a cornerstone technique in animation and video production, has widespread applications in various tasks like text-to-motion and music-to-dance. Previous works focus on developing specialist models tailored for each task without scalability. In this work, we present Large Motion Model (LMM), a motion-centric, multi-modal framework that unifies mainstream motion generation tasks into a generalist model. A unified motion model is appealing since it can leverage a wide range of motion data to achieve broad generalization beyond a single task. However, it is also challenging due to the heterogeneous nature of substantially different motion data and tasks. LMM tackles these challenges from three principled aspects: 1) Data: We consolidate datasets with different modalities, formats and tasks into a comprehensive yet unified motion generation dataset, MotionVerse, comprising 10 tasks, 16 datasets, a total of 320k sequences, and 100 million frames. 2) Architecture: We design an articulated attention mechanism ArtAttention that incorporates body part-aware modeling into Diffusion Transformer backbone. 3) Pre-Training: We propose a novel pre-training strategy for LMM, which employs variable frame rates and masking forms, to better exploit knowledge from diverse training data. Extensive experiments demonstrate that our generalist LMM achieves competitive performance across various standard motion generation tasks over state-of-the-art specialist models. Notably, LMM exhibits strong generalization capabilities and emerging properties across many unseen tasks. Additionally, our ablation studies reveal valuable insights about training and scaling up large motion models for future research.
MotionVerse
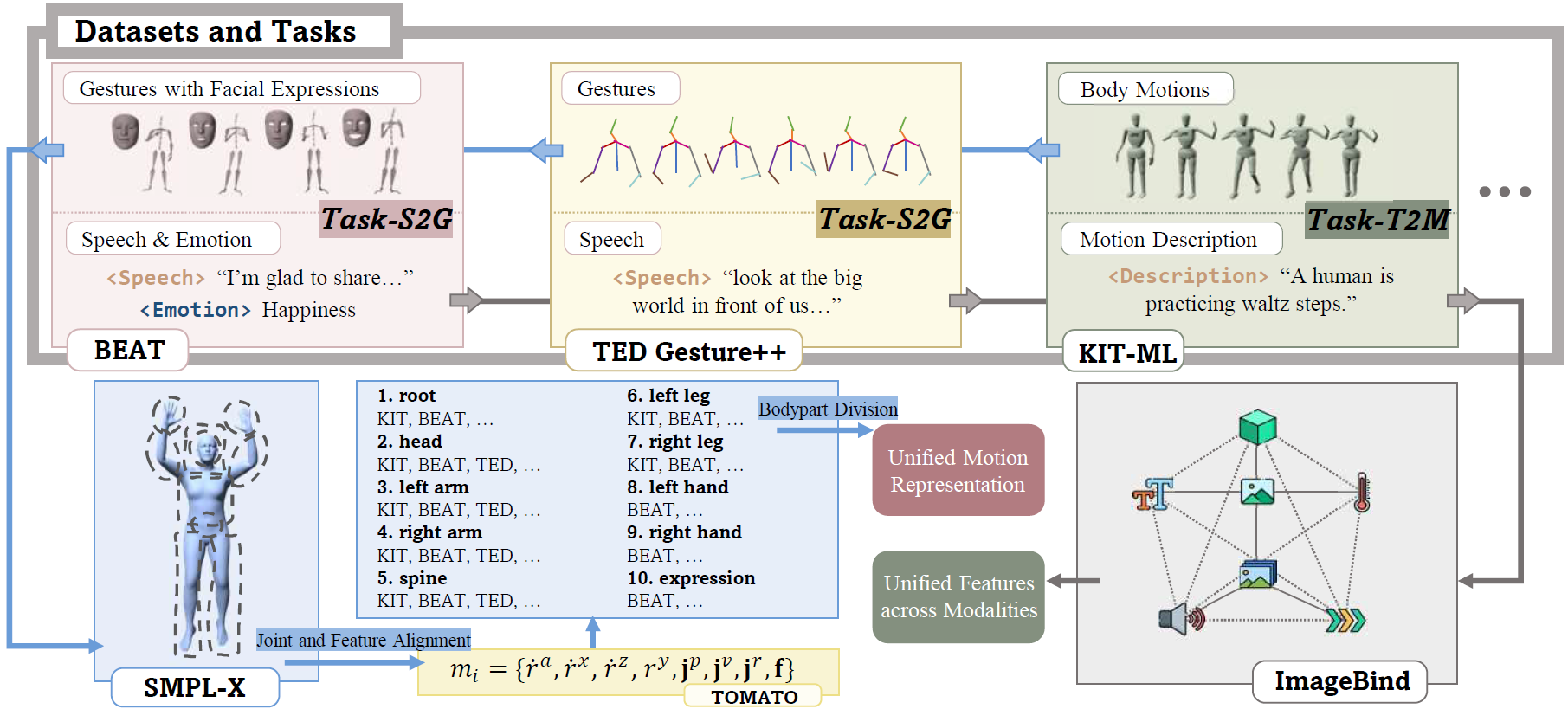
MotionVerse is a comprehensive benchmark, comprising 10 tasks, 16 datasets, a total of 320k sequences, and 100 million frames. We preprocess distinct motion-centric datasets into a unified format. As for motion sequences, we initially convert them to the TOMATO representation and then further divide them into ten independent body parts, serving as our unified motion representation. To tackle multi-modal condition signals, we employ ImageBind to transform them into unified features across modalities.
Large Motion Model
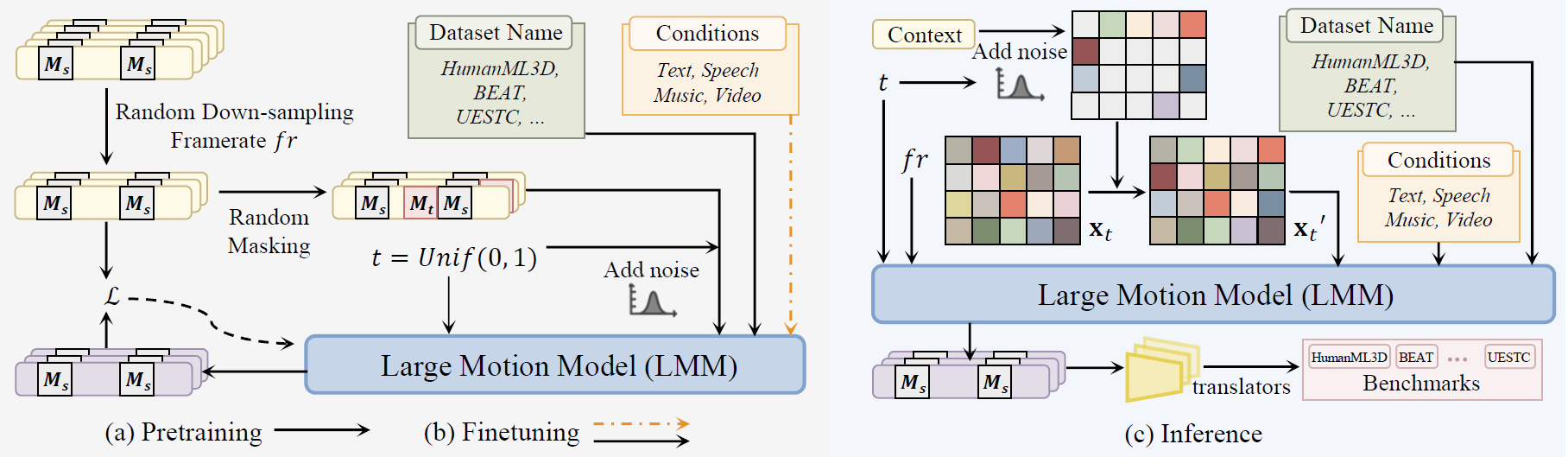
Large Motion Model(LMM) is a diffusion model-based multi-conditional motion generation network. Left: Our two-stage training procedure, including unsupervised pretraining and supervised fine-tuning. Random down-sampling and random mask strategies are applied to enhance knowledge absorption. Right: The generic inference process of LMM. The noised motion sequence and the given context are initially merged before being input into the network. LMM will then synthesize motion sequences, consistent with the provided multi-modal condition signals.
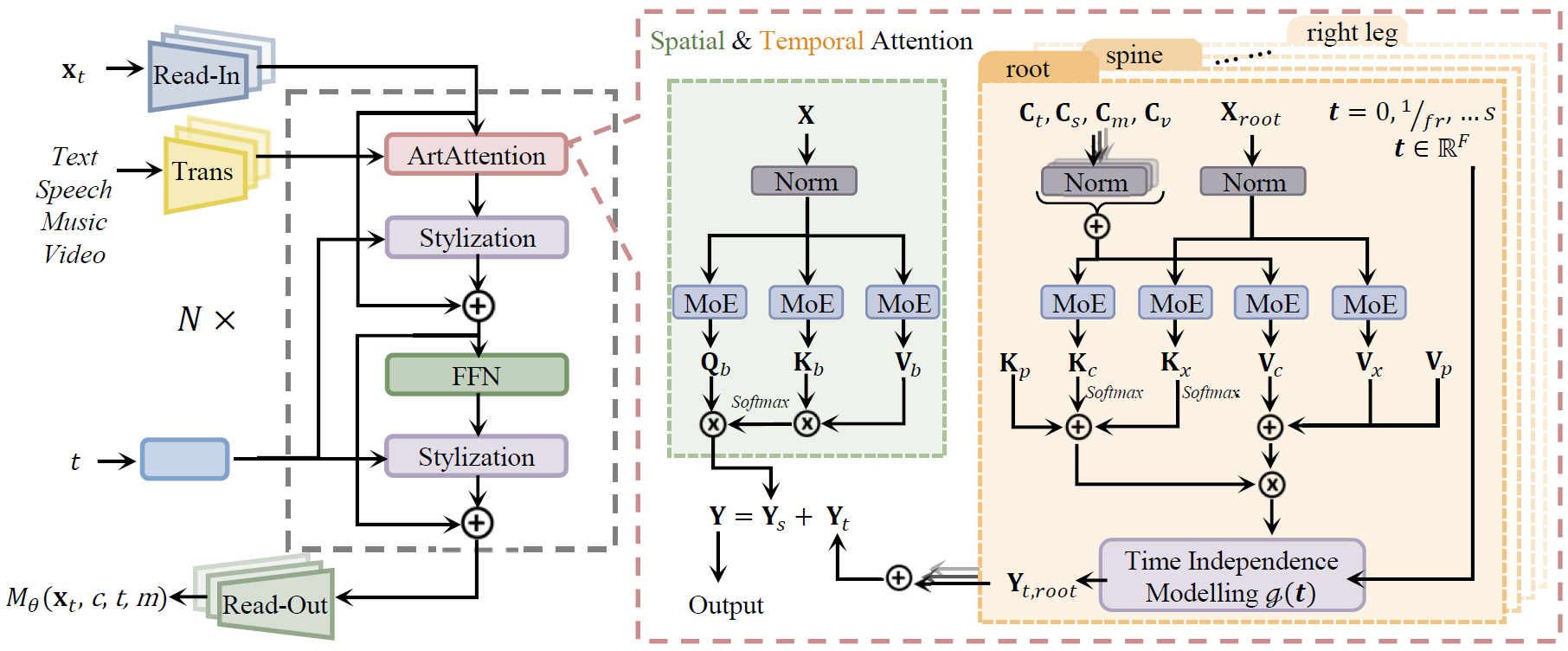
LMM is built on transformer architecture, where ArtAttention serves as the cornerstone, undertaking the core task of integrating multimodal conditions and providing a generic motion prior. It refines the feature representations through the spatial and temporal attention branches, supporting flexible and fine-grained control. Dataset-dependent Read-In layers and Read-Out layers facilitate the conversion of the motion sequence between our intermediate representation and the latent feature space.
Fantastic Human Generation Works 🔥
Motion Generation
⇨ FineMoGen: Fine-Grained Spatio-Temporal Motion Generation and Editing
⇨ InsActor: Instruction-driven Physics-based Characters
⇨ ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
⇨ DiffMimic: Efficient Motion Mimicking with Differentiable Physics
⇨ MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
⇨ Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
2D Human Generation
⇨ Text2Performer: Text-Driven Human Video Generation
⇨ Text2Human: Text-Driven Controllable Human Image Generation
⇨ StyleGAN-Human: A Data-Centric Odyssey of Human Generation
3D Human Generation
⇨ EVA3D: Compositional 3D Human Generation from 2D Image Collections
⇨ AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
BibTeX
@article{zhang2024large,
title = {Large Motion Model for Unified Multi-Modal Motion Generation},
author = {Zhang, Mingyuan and
Jin, Daisheng around
Gu, Chenyang,
Hong, Fangzhou and
Cai, Zhongang and
Huang, Jingfang and
Zhang, Chongzhi and
Guo, Xinying and
Yang, Lei and,
He, Ying and,
Liu, Ziwei},
year = {2024},
journal = {arXiv preprint arXiv:2404.01284},
}Acknowledgement
This study is supported by the Ministry of Education, Singapore, under its MOE AcRF Tier 2 (MOET2EP20221- 0012), NTU NAP, and under the RIE2020 Industry Alignment Fund – Industry Collaboration Projects (IAF-ICP) Funding Initiative, as well as cash and in-kind contribution from the industry partner(s).
We referred to the project page of Nerfies when creating this project page.